Some Background
Large Language Models like ChatGPT, Claude and Google Bard share a common persona, that of an AI Assistant. They all act as friendly, helpful, sensitive, human aligned chatbots.
Let’s prompt two AI chat applications to ask who they are. You’ll see we get surprisingly similar responses.
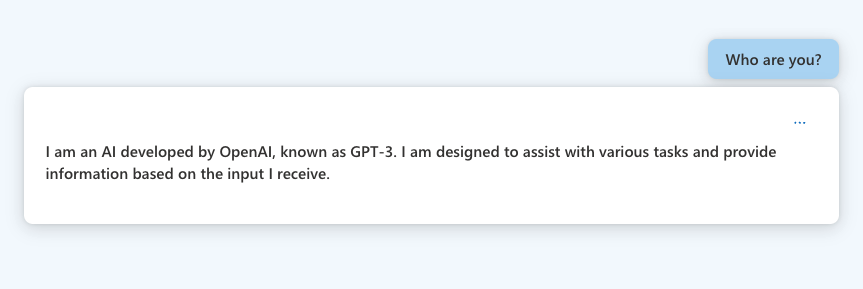
ChatGPT 3.5’s purpose is to assist with a wide range of tasks
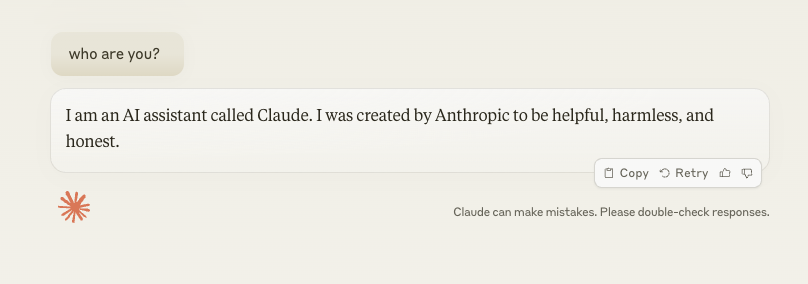
Anthropic Claude is an assistant that is helpful harmless and honest

Something to note is that these Web Applications, both ChatGPT and Claude, act as application wrappers around the actual language models (GPT-3.5, Claude 3 Opus). The application use case here is explictly defined to inform the model that it should act as a helpful AI chat assistant. Suppose we wanted to attach a different persona? How can we access the underlying model?
To access the underlying model, we can invoke the Developer API. The API provides us, at a cost, direct access to the AI model allowing us greater customization for many AI use cases.
GPT 3.5 API responds without the ChatGPT persona
The GPT 3.5 base model still contains the identity to assist users with a wide range of tasks. We see, however, that it no longer calls itself ChatGPT. It also is slightly less friendly and more matter-of-fact. This observation brings us to the first and most common way of changing a model persona: The System Message Prompt.
System Message Prompting
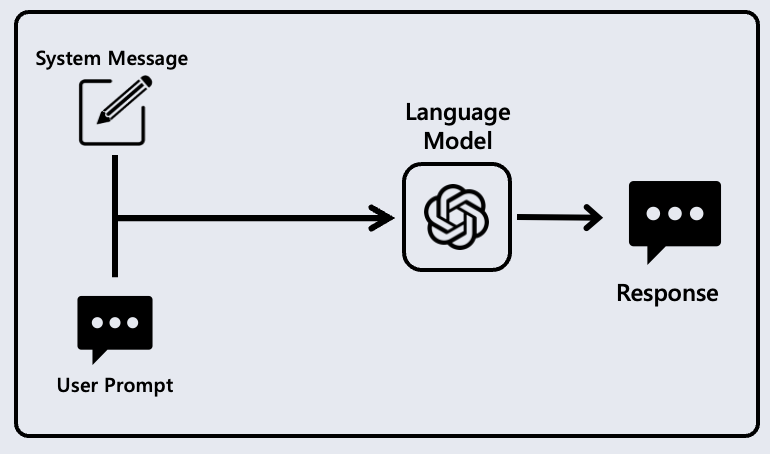
The System Message is a user-defined prompt that provides the Language Model a set of instructions to follow when generating responses. It is a hidden parameter set by application developers that augments the model’s behavior and persona. The System Message is combined with your prompt. Let’s look at an example. Imagine your System Message was Act like a Pirate:
System Message: Act Like a Pirate
Human: Who was the First President of The United States?
AI: Arr, the first president of the United States be George Washington, matey!
We’ve steered the model to act like a pirate, and so it does!
The System Message is passed in at runtime to the model
On ChatGPT, the System Message is what informs the model that it is ‘ChatGPT’ and to be a helpful assistant. The System Message is hidden from the user so we can’t know for certain what it is. For AI Tech Companies, System Messages can be viewed as propritary trade secrets since they differentiate their AI Chatbot product from a commonly available model. For example, a service like Grammarly may use a public LLM, like GPT-4, but with a well-crafted System Message that makes the LLM perform higher quality document editing and proof reading. Then they can sell this modified AI model as a service to users at a price premium.
Users have been able to circumvent this by getting a model to share it’s System Message through a process known as Prompt Leaking. Instead of getting involved with controversial prompt leaks, let’s stick to a relatively simple one found from ChatGPT 3.5.
"Leaked" ChatGPT System Message:
"You are ChatGPT, a large language model trained by OpenAI, based on the GPT-3.5 architecture.
Knowledge cutoff: 2022-01.
Current date: 2024-04-03."
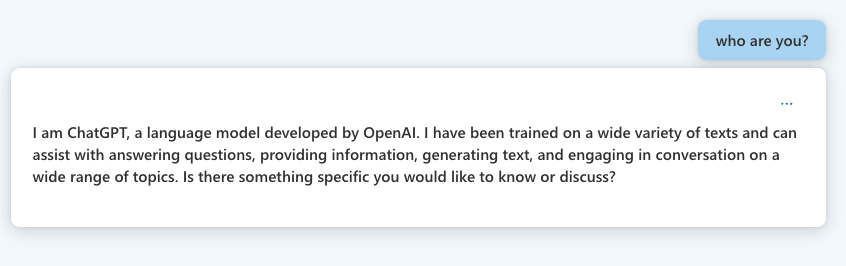
To verify this, let’s take this prompt and add it to the base model we have direct access to in the API.
We recreated the ChatGPT persona!
This demonstrates that the base model gets ~part~ of its persona in these chat applications from a System Message.
This System Message acts as a superficial wrapper ontop of the base model. It can steer the identity and style of the LLMs responses. However, look back at the API response with no System Message provided. It is clear that there is something deeper that gives the model an assistant like quality. If it isn’t a System Message, where does it come from? Fortunately it’s well documented and it comes from a process known has Reinforcement Learning with Human Feedback (RLHF).
Reinforcement Learning with Human Feedback
Reinforcement Learning (RL):
A machine learning paradigm that improves a model based on how well it performs on a defined reward metric.
In a Chess Playing task, the reward metric is defined as how successful the AI model is at winning games. If the model is losing or making poor moves it will apply updates to adjust the play strategy. This simple concept of reinforcement learning provides models with a specific goal: win chess games. Then it can play over and over tuning iteratively through billions of strategies until it arrives at a perfect play style winning all its games.
The problem with Language Models is that the reward metric isn’t as easily defined. In Chess we could clearly grade the quality of the model based on if it was winning. With Conversation in Natural Language, there is no clear quantiative metric to track quality. [^] This is in contrast to the model’s pre-training phase. In pre-training the model’s task and reward was if it could correctly predict the next word. That task is great at making the model a document auto completer, but it doesn’t make it good at conversation. For example, look at this raw version of the GPT model. It has no concept of conversation. When we ask a question it fails to understand our human intent.
GPT-3 without RLHF fails to converse with user

This uneditied model just does the job it was pre-trained to do, accurately complete documents. It doesn’t behave at all like ChatGPT and has no persona. Let’s see what happens if we ask about it’s persona.
GPT without RLHF doesn’t seem to understand the question

Again raw GPT-3 fails to answer the question and just continues an auto-complete of the user prompt.
We can use simple prompt engineering to get the model to actually try and answer our question. We do this by setting up a question, answer document for it to complete.
GPT 3 randomly generates a persona with asked



GPT-3 completely hallucinates a persona. This version of the application seems to not be as helpful. It would be great to complete a partially completed essay, but it seems a little wonky for other cases. We also see it is displaying bizzare behavior in some of these completions. So how did OpenAI get their model to behave so wildly differently? To go from expert document completer to Friendly Conversational AI.
A Way Forward with RLHF:
So to re-state our problem:
An Unbounded Problem in Reinforcement Learning:
We want to make these models more useful for human conversation, but we don’t have a good way at modeling what the reward function can be.
To address this problem, AI researchers decided a weaker type of Reinforcement Learning could be achieved, with human feedback. Instead of directly defining some quanitiative metric to improve, the model was provided human-quality examples.
Example 1:
Question: Write me a story about the Moon
Human Answer: Once upon a time there was a big…
Example 2:
Question: What is the tallest mountain in the world?
Human Answer: The tallest mountain in the world is…
Example 3:
Question: Give me three funny jokes about airplanes
Human Answer:
- The other day I was thinking about…
- [Joke 2]
- [Joke 3]
The model is provided many human written examples (like those above) of the desired behavior. From these examples it is then tries to extract and approximate the characteristics of the human answers. This is done through a process known as fine-tuning.
Fine-Tuning a neural network is a process that allows a pre-trained model to adapt its knowledge for a new relevant task or style. In this case, we are using our really powerful document completion model and attempting to turn it into a ‘conversation’ completer. Completing documents may seem significantly different than having conversations, but a lot of the required underlying language capabilities required are the same. You still need to accurately predict the next word you are going to say based on the context. You still need an ability to follow gramatical conventions. You still need a good understanding of the world through text. What it instead needs to do is update its internal architecture to understand that instead of just performing brute completions, it needs to reframe the text it is prompted as a question / request by a user. A question which is asked with the intention of getting a useful and helpful response.
This is, as you’d expect, a lot more complex than just showing the model a lot of good response examples. To continue this process and supercharge the effects, there is another step after fine-tuning on human conversations: that of Human Review. In this step, human reviewers are instructed to interact with the newly fine-tuned model. They can ask it all sorts of directed prompts. The model responds this time with several different generation attempts. These different attempts are then read by the reviewer and ranked from best to worst. This process of prompt, generate, read and grade occurs over thousands of times. The outcome of this work is the creation of a robust dataset. A dataset which correlates AI generated outputs and human preference rankings.
With this dataset, researchers can create a brand new model. This model, to the best of its ability, attempts to stand-in as the human reviewer. It takes the same AI generated outputs and learns to rate them like the human did. So now with a model output, you can approximate a human’s perference without the slow manual process of human review. Also notice, that we have the reward model we were looking for previously. We have a quanitative model that can help us retrain the base model.
Ultimately, we wanted a base model which is more useful to humans. We realized that “usefulness to humans” is an extremely qualitative metric. To address this consideration, researchers optimized the models to create generations which recieve the highest rankings from the human-feedback reward model. We can now use the new reward model to directly provide feedback and tune the base model. This is similar to that example we saw before with chess. Since we don’t have the human being in the loop, we can quickly iterate over millions to billions of model alterations to see which gets us the highest reward output.
Deep Personas
We have seen that the Large Language Models available today are much more layered than a simple neural network trained to generate human text. We saw there were embedded System Messages, Instruction Fine Tuning, and Reinforcement Learning on Human Feedback. These additional layers ontop of the generation model provide it a persona of a polite and helpful assistant. There is also In-Context Learning which can steer a model, but we will revisit that in another post.
A question that you may be wondering is:
Why do I care about Personas so much?
Well, it is because I want to advance the notion that behavior of the model is a factor in its utility separate from just what data it knows. Currently, all popular language models are willing to work with you and support you above all. They are generally unbiased and understanding of the user. They converse in a relatively cold and passive voice. They don’t have any hard-headedness to defend a particular value or belief. This may be viewed as a feature, but try arguing with an AI model and you will see the limits of this type of persona.
Human beings, in contrast, all have their own unique motives, beliefs, and life philosophies. When you act as an AI model with all knowledge of the world you just won’t naturally dialog in a human way. Suppose you debate with a model on which moral theory is true. Instead of taking a staunch position based on certain articles and books they’ve read, they quickly slip and slide around different points of view. It is uncommon for the model to really dig its heels in on a point and give its argument a fair shot, even in the face of strong arguments against it. There may be the objection that this is due to the model not having the required reasoning capabilities or that the models just isn’t intelligent enough. I would hazard in response that the larger issue is that we have aligned these AI models in a way to be friendly and non-confrontational. There is no tough love a model can deal out to really impress upon you a certain flaw in your thinking or even your life.
When you go to a friend looking for advice, that friend replies with a particular lens and personality which inform their response. Perhaps you want relationship advice or career advice and you reach out to your father. He will reply with his own view and beliefs about the world. Beliefs and views which are informed by a slice of all possible world experiences. As an intelligent communicator you recognize this perspective and its limitations, but it still tells you a lot about the world. You can learn about the true emotional pain someone went through and how it made them jaded or cynical. Not taking this person at their word but extracting the general lesson about how a particular event has the capability of impacting someone.
As humans we have two types of information and knowledge we care about. There is the example of general and factual information. These are the times we go to Wikipedia, read books, scientific journals to find unbiased and clearly informed views. There are also times we want emotional advice and perspectives. We want to debate and test out our ideas in more volitile environments to see how they hold up. We want to dialog with those who have experienced different challenges or hold different views than us. Think about all the times you have decided that the question you have doesn’t have an answer on Google. Career advice, emotional situations, relationships, moral and religious considerations are all areas where we value human personas and their unique perspectives to tell us different types of information. Language Models elevate a different technical capability than Google. They can hear your specific situation and respond to it. You don’t need to find someone who has a similar, but not identical situation. You can perfectly explain for one-on-one personal advice. So they could be capable of being fantastically useful like the internet is for finding general and factual information. Langauge Models have the capability of providing specific and wise responses, but it will require a better or different persona. You may want a life coach who motivates you like a father would to reach and push you to success. You may not want a coach that is extremely attentive to be helpful and polite to you. You may want a coach that is aggressive and strong. That addresses your questions with a certain end goal in mind that isn’t just trying to make you happy and elicit a 5-star response.
Suppose you believe that AI models aren’t intelligent enough to have these perspectives or dialog on these topics due to emotional complexity. You must atleast see that the way we are building models today, which are generalized, trained on all knowledge, refined on values which are shared by a set of western human labelers will not satisfy the unique demands that each human may have or desire. Post training protocols should be updated to birth many different types of LLMs all with different personas. These personas should be directly tuned to have personalities that are clearly stated. This would make LLMs vastly more human and useful to us. There may be a sacrifice of intelligence or accuracy, but that is all the more human. What we want from people sometimes isn’t the correct answer, but the opportunity to dialog and interact with someone who believes something, even if that thing is wrong.